Для начала давайте ознакомимся с одноименной статьей Матюхина Виктора Александровича.
Особо стоит обратить внимание на рисунок, который описывает суть всего подхода 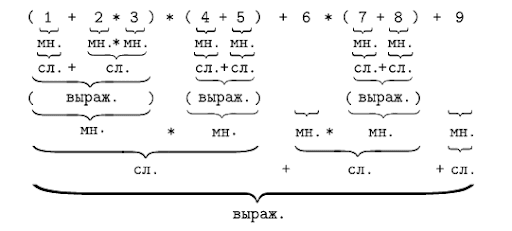
Практиковать навыки по этой теме будет на задаче 451(acmp.ru)
Составим нотацию Бекуса-Наура для арифметического выражения, представленного в этой задаче.
1. <Выражение> = <Слагаемое>{(+|-)<Слагаемое>}
2. <Слагаемое> = <Множитель>{(*|/)<Множитель>}
3. <Множитель> = (+|-) <ДробноеЧисло>|<Функция>|(<Выражение>)
4. <ДробноеЧисло> = <ЦелаяЧасть>|<ЦелаяЧасть>.<ДробнаяЧасть>
5. <ЦелаяЧасть> = <Цифра>|<Цифра><Цифра>
6. <ДробнаяЧасть> = <Цифра>|<Цифра><Цифра>
7. <Функция> = <ИмяФункции>(<Выражение>)
8. <ИмяФункции> = "sin"|"cos"
9. <Цифра> = 0|1|2|3|4|5|6|7|8|9
Можно заменить, что дробное число может быть представлено либо целым числом, состоящим, как минимум из одной цифры, либо “составным”, состоящим из целой части и дробной. При этом и целая и дробная часть должна состоять, как минимум из одной цифры. Отсюда можно сделать следующие выводы:
1) Число может содержать ведущие нули (например 0056.89). Это более чем валидно.
2) Числа вида “56.” или “.89” не являются валидными. С++сный компилятор жует такое с причмокиванием, но ругается на “.” (и это не может не радовать =) ). Компилятор FreePascal понимает только “56.”. Для решения данной задачи будем считать такие числа невалидными.
3) в третьей записи знаки плюс и минус стоит расценивать исключительно как унарные.
Есть два момента, которые затрудняют решение данной задачи:
1)выражение может содержать ошибки
2)наличие разделителей(пробелов), которые могут повлиять на корректность вычислений.
В разборе к данной задаче сказано, что первым делом нужно удалить все встречающиеся пробелы. Это неверный подход, потому что пробелы могут находится в имени функции (“s in” != “sin”) или в определении числа (“5 6. 89” != “56.89”). Такие случаи нужно корректно обрабатывать.
Рассмотрим два подхода к реализации.
Первый будет основан на статье, представленной в начале поста, в которой явно выделяется следующая лексема.
Второй отличается от первого только тем, что лексема явно не получается, а формируется по ходу дела.
Первый подход предпочтительней по следующим причинам:
1)нет возни с разделителями.
2)перевод из строки в дробное число можно возложить на встроенные функции, например sscanf.
3)работу с лексемами легко приспособить под string
Но есть один минус. При получении каждой составляющей выражения нужно гарантировать, что первая лексема этой составляющей уже считана.
Поэтому если гарантировалось, что пробелов нет, я бы предпочел второй подход. Хотя это уже скорее дело вкуса.
Отмечу еще такой факт, что при реализации второго подхода выражение удобно хранить в виде char*, и при разборе выражения последовательно двигать указатель, ссылающийся на начало выражения.
Реализация второго подхода: 451_nolex_ac.cpp Т.к. в условии задачи используются только функции косинус и синус с прототипом double func(double), то в обоих реализациях было удобно одновременно хранить указатели на функции и их строковые представления:
- char* funcName[] = {"sin","cos",0};
- double (*pfuncs[])(double) = {sin,cos};
* This source code was highlighted with Source Code Highlighter.Такой подход очень удобен и масштабируем. Если нужно будет добавить еще одну функцию с таким прототипом, то нужно будет пополнить значения двух массивов. Остальной код не нуждается в изменениях.
P.S: На самом деле метод рекурсивного спуска для этой задачи – не самое удачное решение. Здесь много подводных камней и писанины. Но для того, чтобы осознать глубину подхода и развить внимательность – самое то.
В качестве альтернативы могу предложить более простую задачу с точки зрения реализации 14F. Электронная таблица (Меньшиков)

Здравствуйте, Игорь!
ОтветитьУдалитьУ меня такой вопрос по реализации рекурсивного спуска: в моей задаче кроме арифметического выражения приходится вычислять также логическое. Оно определяется следующим образом:
::= {'or' }
::= {'and' ::= 'not' | (< | <= | > | >= | == | != ) | ()
Я пытаюсь делать это с помощью лексемы (как в первом решении), но у меня возникает трудность при вычислении , когда текущая лексема - открывающая скобка. В таком случае эта скобка может относиться либо к опять же (Логическому выражению) , либо к первой части сравнения , т.е. (Арифметическому).
Это, понятно, играет роль. Например:
...(a + b > 10)
и
...(a + b) > 13
В первом случае мы "зайдём" в скобки как бы по логическому выражению. Если зайдём так же во втором, то получится неопределненность.
Как мне быть? Спасибо :)
В предыдущем посте почему-то не вставились сами формы:
ОтветитьУдалить< Логическое выражение > ::= < Конъюкция > {or < Конъюкция >}
< Конъюкция > ::= < Логическое условие > {and < Логическое условие >}
< Логическое условие > ::= not < Логическое условие> | < Арифметическое выражение > (< | <= | > | >= | == | != ) < Арифметическое выражение > | (< Логическое выражение >)
Сергей, я бы вам порекомендовал ознакомиться с книгой Шилдта: Искусство программирования на С++ (http://www.ozon.ru/context/detail/id/2260656/ ). В этой книге в одной из глав описывается разработка интерпретатора для С++(minicpp), поддерживающий минимальный набор функций. Но тем не менее этот интерпретатор способен выполнить рекурсивные функции, там точно поддерживается рекурсивный спуск считающий арифметические выражения, и если мне не изменяет память то он справляется и с логическими выражениями.
ОтветитьУдалить